
Każdy właściciel strony internetowej prędzej czy później dochodzi do momentu, w którym zaczyna zastanawiać się, co tak naprawdę dzieje się na jego serwerze, gdy nikt z ludzi go nie odwiedza. To właśnie wtedy do gry wchodzą roboty Google, które są nieustannie głodne nowych treści i niezmordowanie przemierzają cyfrowy świat, by karmić potężne algorytmy wyszukiwarki. Zrozumienie tej relacji przypomina trochę naukę języka obcego – na początku wydaje się trudne i pełne dziwnych reguł, ale gdy już złapiesz podstawy, otwiera się przed tobą mnóstwo nowych możliwości. Interakcja robotów z twoją witryną to nie jest proces jednostronny, gdzie ty tylko publikujesz, a Google tylko czyta. To dynamiczna wymiana danych, która, jeśli nie jest odpowiednio nadzorowana, może doprowadzić do zadyszki twojego serwera. Wyobraź sobie, że Googlebot to bardzo szybki i dokładny czytelnik, który wchodzi do biblioteki, jaką jest twoja strona, i zaczyna przeglądać każdą książkę po kolei. Jeśli twoja biblioteka ma wąskie korytarze, czyli słaby serwer, ten entuzjastyczny czytelnik może zablokować przejście innym użytkownikom. Dlatego tak kluczowe jest, abyś przejął stery i nie zostawiał wszystkiego przypadkowi. Świadome zarządzanie tym ruchem pozwala ci decydować, które drzwi otworzyć szeroko, a które lepiej przymknąć, by chronić prywatne dane lub zasoby techniczne. To wiedza, która daje ci realną władzę nad tym, jak jesteś postrzegany w sieci, bo przecież od tego, co i jak szybko Google zaindeksuje, zależy twoja pozycja w wynikach wyszukiwania, a w konsekwencji ruch na stronie i twoje zarobki. Pamiętaj, że ekosystem Google to nie tylko niebieskie linki w wyszukiwarce, to także mapy, grafika, newsy i coraz częściej sztuczna inteligencja, a każdy z tych elementów potrzebuje nieco innego paliwa w postaci danych z twojej witryny.
UWAGA : Według raportów bezpieczeństwa (np. Imperva Bad Bot Report 2024), prawie 50% (dokładnie 49.6%) całego ruchu w internecie generują boty, z czego około 32% to „złe boty”, a tylko niespełna 18% to „dobre boty” (jak Googlebot). To pokazuje skalę problemu z odróżnieniem ziarna od plew.
Źródło: Imperva 2024 Bad Bot Report
Weryfikowanie żądań od robotów i modułów pobierania Google dla bezpieczeństwa
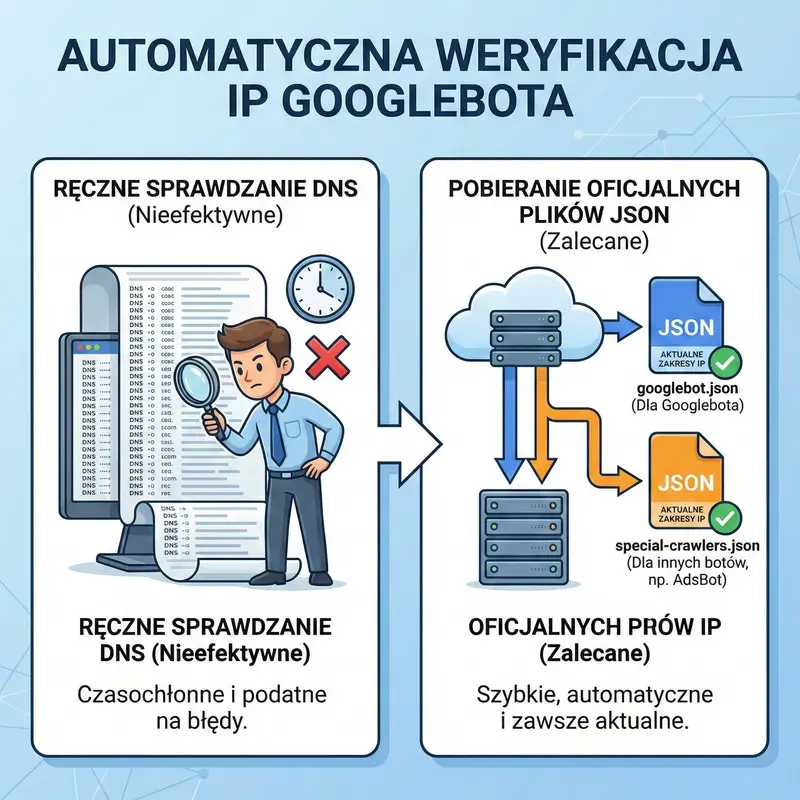
W dzisiejszym internecie nie wszystko jest tym, czym się wydaje na pierwszy rzut oka, i ta zasada dotyczy również robotów odwiedzających twoją stronę. Często zdarza się, że w logach serwera widzisz wizytę podpisaną jako Googlebot, ale w rzeczywistości może to być złośliwe oprogramowanie, które jedynie podszywa się pod zaufanego gościa, by szukać dziur w twoich zabezpieczeniach. Dlatego umiejętność odróżnienia prawdziwego robota od fałszywego przebierańca jest jedną z najważniejszych kompetencji administratora. Nie możesz ufać ślepo nagłówkowi User-Agent, bo jego sfałszowanie jest banalnie proste i zajmuje hakerowi dosłownie sekundy. Jedyną pewną metodą na sprawdzenie tożsamości cyfrowego gościa jest procedura weryfikacji DNS, która działa trochę jak sprawdzenie dowodu osobistego na bramce w klubie. Musisz wykonać tak zwane odwrotne wyszukiwanie DNS dla adresu IP, z którego przyszło zapytanie, i sprawdzić, czy rzeczywiście prowadzi ono do domeny należącej do Google. Ale to jeszcze nie koniec, bo sprytni oszuści potrafią manipulować różnymi elementami, dlatego drugim, niezbędnym krokiem jest sprawdzenie, czy ta domena z powrotem wskazuje na ten sam adres IP. Dopiero gdy ta pętla się domknie i wszystko do siebie pasuje, możesz mieć stuprocentową pewność, że masz do czynienia z oficjalnym robotem. Dla osób, które zarządzają dużymi serwerami i nie mają czasu na ręczne sprawdzanie każdego adresu, Google udostępnia listy swoich adresów IP, co pozwala na automatyzację tego procesu na poziomie firewalla. Ignorowanie tego aspektu to proszenie się o kłopoty, bo możesz przez pomyłkę zablokować prawdziwego robota, myśląc, że to atak, i zniknąć z wyników wyszukiwania, albo wpuścić szkodnika, który spowolni twoją stronę, kradnąc zasoby przeznaczone dla klientów. Bezpieczeństwo twojej witryny zależy od tego, jak szczelne sito zastosujesz wobec tych automatów, dlatego warto poświęcić chwilę na konfigurację mechanizmów weryfikacji.
UWAGA : Zamiast ręcznie sprawdzać DNS, administratorzy mogą pobrać oficjalny plik googlebot.json, który zawiera aktualne zakresy adresów IP. Warto dodać, że Google publikuje też osobny plik special-crawlers.json dla innych botów (np. AdsBot).
Źródło: Dokumentacja Google Search Central – Weryfikowanie Googlebota
Zmniejszanie szybkości indeksowania przez Google w razie problemów z serwerem
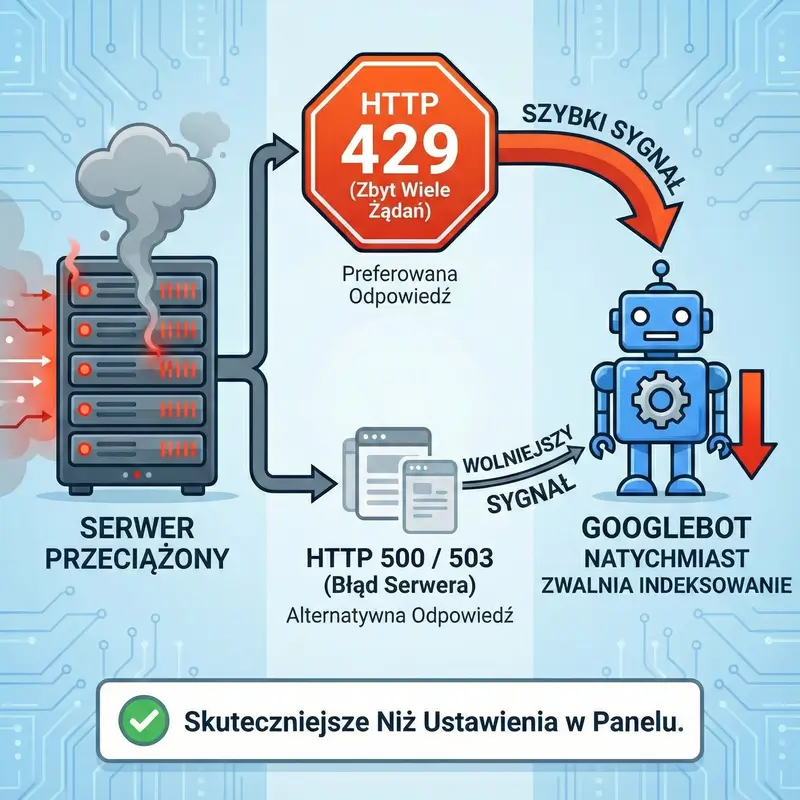
Nawet najlepiej skonfigurowany serwer ma swoje limity wytrzymałości i czasami zdarzają się sytuacje awaryjne, w których nadmierna aktywność robotów Google może stać się gwoździem do trumny dla wydajności twojej strony. Choć algorytmy Google są mądre i teoretycznie powinny same wyczuć, że twoja strona „ledwo zipie”, zwalniając tempo pobierania, to w praktyce ten automat nie zawsze reaguje wystarczająco szybko. Właśnie na takie momenty przygotowano specjalne narzędzie w Google Search Console, które działa jak hamulec bezpieczeństwa w pociągu. Jeśli widzisz, że twoja strona ładuje się wieki, a statystyki pokazują gigantyczny skok aktywności botów, możesz ręcznie poprosić o zmniejszenie częstotliwości odwiedzin. To rozwiązanie jest jednak ostatecznością i powinno być traktowane jak leczenie objawowe, a nie stała strategia optymalizacji. Musisz mieć świadomość, że pociągnięcie za ten hamulec ma swoje konsekwencje, bo spowolnienie robotów oznacza, że Google wolniej dowie się o twoich nowych artykułach czy zmianach cen produktów. Efekt użycia tego narzędzia nie jest też natychmiastowy i może minąć nawet do dwóch dni, zanim machina Google w pełni zwolni obroty, co w świecie internetu może wydawać się wiecznością. Co więcej, to ustawienie jest tymczasowe i zazwyczaj wygasa po pewnym czasie, przywracając automatyczne sterowanie, co ma sens, bo Google chce jak najszybciej wrócić do normalnego trybu pracy, by dostarczać użytkownikom świeże informacje. Warto też wiedzieć, że kij ma dwa końce i nie da się w ten sposób wymusić na Google szybszego indeksowania, jeśli serwer działa dobrze – prośba o przyspieszenie powyżej tego, co algorytm uważa za bezpieczne, po prostu nie zadziała. Traktuj więc tę opcję jako koło ratunkowe na czas migracji serwera czy poważnych prac technicznych, ale na co dzień skup się raczej na optymalizacji kodu strony, żeby roboty mogły ją „trawić” szybciej i bezproblemowo, nie obciążając przy tym infrastruktury.
UWAGA : Jeśli serwer jest przeciążony, powinien zwracać kod statusu HTTP 429 (Too Many Requests) lub ewentualnie 500/503. Googlebot traktuje kod 429 jako wyraźny sygnał do natychmiastowego zmniejszenia częstotliwości żądań. Jest to szybsze i skuteczniejsze niż ustawienia w panelu.
Źródło: Dokumentacja Google Search Central – Zmniejszanie szybkości indeksowania
Zarządzanie indeksowaniem za pomocą pliku robots txt krok po kroku

Plik robots.txt to chyba jeden z najbardziej niedocenianych, a zarazem potężnych elementów każdej strony internetowej, pełniący rolę recepcjonisty, który wskazuje drogę wchodzącym gościom. To właśnie w tym niepozornym pliku tekstowym, który znajduje się w głównym katalogu twojej domeny, ustalasz zasady gry, mówiąc robotom, gdzie mogą wejść, a które pokoje są dla nich zamknięte na klucz. Jego konstrukcja jest prosta, ale jeden mały błąd w składni, na przykład postawienie ukośnika w złym miejscu, może sprawić, że cała twoja witryna zniknie z indeksu Google, dlatego edytowanie go wymaga skupienia i precyzji. Używasz w nim głównie dwóch komend: Allow, czyli pozwalaj, oraz Disallow, czyli zabraniaj, i łączysz je z nazwą konkretnego robota, co daje ci ogromną elastyczność w zarządzaniu ruchem. Dzięki temu możesz na przykład zablokować dostęp do panelu logowania, koszyka zakupowego czy wyników wewnętrznej wyszukiwarki, które nie mają żadnej wartości dla kogoś, kto szuka informacji w Google, a ich indeksowanie tylko marnowałoby zasoby twojego serwera. Pamiętaj jednak, że zablokowanie strony w robots.txt nie jest równoznaczne z usunięciem jej z Google; to jedynie informacja dla robota „nie wchodź tutaj i nie pobieraj treści”, ale jeśli ktoś inny zalinkuje do tej strony, to jej adres wciąż może się wyświetlić w wynikach wyszukiwania, tylko bez opisu. Jeśli chcesz coś trwale ukryć, musisz pozwolić robotowi wejść na stronę i odczytać specjalny tag „noindex”, co wydaje się sprzeczne z intuicją, ale tak właśnie działa ta technologia. Mądre wykorzystanie tego pliku pozwala ci też wskazać robotom mapę witryny, co jest jak wręczenie im gotowego planu budynku, dzięki czemu szybciej trafią do najważniejszych dla ciebie treści. Traktuj robots.txt jak narzędzie do optymalizacji budżetu indeksowania, czyli czasu, jaki Google chce poświęcić twojej stronie – im mniej czasu robot zmarnuje na śmieciowe podstrony, tym więcej go zostanie na te, które realnie sprzedają twoje usługi lub produkty.
UWAGA : Googlebot przetwarza tylko pierwsze 500 KiB (kilobajtów) pliku robots.txt. Wszystko, co znajduje się poniżej tej granicy, zostanie całkowicie zignorowane. Jeśli masz bardzo rozbudowane reguły, musisz o tym pamiętać, bo kluczowa blokada na końcu pliku może nie zadziałać.
Źródło: Dokumentacja Google Search Central – Specyfikacje pliku robots.txt
UWAGA :Googlebot przechowuje kopię pliku robots.txt w pamięci podręcznej zazwyczaj przez 24 godziny. Oznacza to, że jeśli zaktualizujesz plik, aby odblokować ważną podstronę, robot może tego nie zauważyć przez całą dobę, chyba że ręcznie wymusisz odświeżenie w narzędziu Tester pliku robots.txt.
Źródło: Dokumentacja Google Search Central – Tworzenie pliku robots.txt
Jak preferencje indeksowania wpływają na to gdzie twoja witryna pojawia się w Google
Wielu ludziom wydaje się, że Google to jedna wielka machina, ale w rzeczywistości to skomplikowany system naczyń połączonych, gdzie decyzja podjęta w jednym miejscu ma wpływ na widoczność w zupełnie innych usługach. Kiedy konfigurujesz dostęp dla robotów, musisz myśleć szeroko, bo blokując głównego Googlebota, możesz niechcący odciąć się nie tylko od wyników wyszukiwania tekstu, ale też od Zakupów Google, Discovera czy Grafik. Wszystkie te usługi czerpią z tej samej bazy danych, którą budują roboty, więc jeśli zamkniesz im drzwi, twoje treści przestaną płynąć do całego ekosystemu. Na przykład, jeśli prowadzisz sklep internetowy i zablokujesz dostęp do zdjęć produktów, by zaoszczędzić transfer, możesz nagle zniknąć z Google Grafika, co dla branży e-commerce bywa bolesne, bo wielu klientów kupuje oczami. Z kolei wydawcy portali newsowych muszą dbać o to, by ich artykuły były błyskawicznie dostępne dla robotów, bo tylko wtedy mają szansę trafić do feedu Discover na telefonach milionów użytkowników, co potrafi wygenerować gigantyczny ruch w krótkim czasie. Każda usługa Google ma swoje specyficzne wymagania, ale wspólnym mianownikiem jest dostępność – jeśli robot nie może pobrać strony i zrozumieć jej zawartości, to żaden magiczny trik SEO nie sprawi, że pojawi się ona wysoko w rankingu. Dlatego tak ważne jest, aby nie przesadzić z restrykcjami i nie blokować zasobów takich jak pliki CSS czy JavaScript, które są niezbędne robotom do tego, by „widziały” stronę tak samo jak człowiek. Jeśli robot zobaczy tylko goły kod HTML bez stylów, może uznać twoją stronę za niefunkcjonalną lub przestarzałą, co odbije się na twojej pozycji. Zarządzanie tymi preferencjami to ciągłe balansowanie między ochroną prywatności i zasobów serwera a chęcią bycia widocznym wszędzie tam, gdzie mogą być twoi potencjalni klienci. Dobre zrozumienie tych zależności pozwala budować strategię, w której twoja treść pracuje na ciebie na wielu frontach jednocześnie, od klasycznej wyszukiwarki po nowoczesne asystenty głosowe i karty informacyjne.
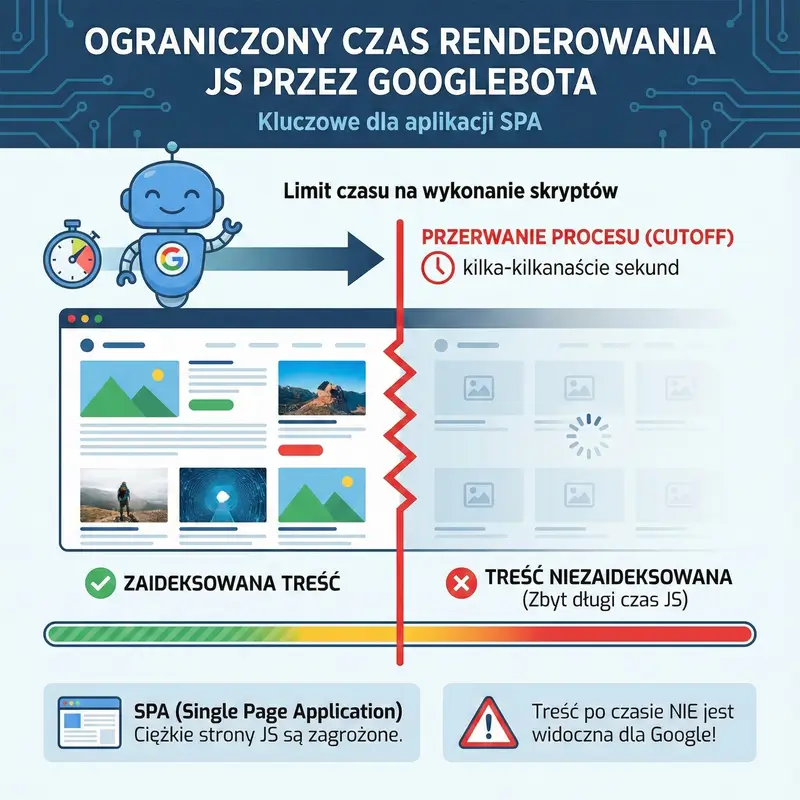
UWAGA :Googlebot ma ograniczony czas na renderowanie JavaScriptu na stronie. Jeśli skrypty wykonują się zbyt długo (zazwyczaj mowa o kilku-kilkunastu sekundach, choć Google nie podaje sztywnej liczby „cutoff”), proces renderowania zostanie przerwany, a treść wygenerowana później nie zostanie zaindeksowana. To kluczowe dla ciężkich stron typu SPA (Single Page Application).
Źródło: Dokumentacja Google Search Central – Rozwiązywanie problemów z JavaScriptem w wyszukiwarce
Nowe wyzwania czyli Google Extended i sztuczna inteligencja Gemini
Świat idzie do przodu i dzisiaj musimy martwić się nie tylko o to, jak widzi nas klasyczna wyszukiwarka, ale też o to, jak nasze treści są mielone przez potężne modele sztucznej inteligencji. Pojawienie się narzędzi takich jak Gemini czy ChatGPT sprawiło, że Google wprowadziło nowe mechanizmy kontroli, dając twórcom wybór, czy chcą karmić te cyfrowe mózgi swoją ciężką pracą. Tutaj na scenę wkracza Google-Extended, czyli specjalny identyfikator robota, który pozwala ci powiedzieć „stop” modelom AI, nie znikając jednocześnie z normalnych wyników wyszukiwania. To bardzo ważne rozróżnienie, bo wielu właścicieli stron chce, aby ludzie trafiali do nich przez Google, ale niekoniecznie chcą, by ich unikalne teksty służyły do trenowania sztucznej inteligencji, która potem może odpowiadać na pytania użytkowników bez odsyłania ich do źródła. Użycie Google-Extended w pliku robots.txt to swego rodzaju deklaracja niepodległości twoich danych w erze generatywnego AI. Musisz jednak pamiętać, że technologia rozwija się błyskawicznie i pojawiają się coraz to nowsze usługi, takie jak NotebookLM, które mają swoje własne, specyficzne sposoby pobierania treści na żądanie użytkownika. Dla ciebie jako administratora oznacza to konieczność bycia na bieżąco i ciągłego aktualizowania swojej wiedzy, bo to, co działało rok temu, dzisiaj może być już niewystarczające. Decyzja o zablokowaniu dostępu dla AI nie jest prosta – z jednej strony chronisz swoją własność intelektualną, z drugiej możesz stracić szansę na bycie cytowanym przez asystentów nowej generacji, którzy w przyszłości mogą stać się głównym sposobem, w jaki ludzie szukają informacji. To dylemat strategiczny, a nie tylko techniczny. Warto też obserwować, jak zmieniają się standardy w branży, bo podejście do udostępniania danych modelom językowym wciąż się kształtuje i to, co dzisiaj jest opcją, jutro może stać się standardem. Twoim zadaniem jest świadome sterowanie tym procesem, aby technologia służyła twoim celom biznesowym, a nie odwrotnie.
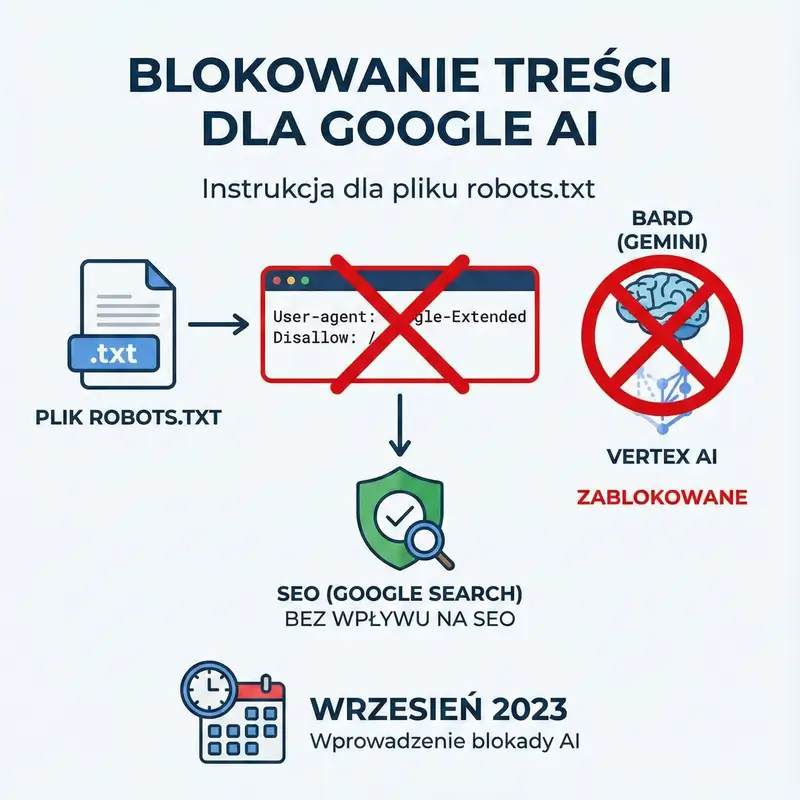
UWAGA :Aby zablokować wykorzystanie treści w produktach AI Google, należy użyć konkretnie dwóch tokenów w pliku robots.txt: User-agent: Google-Extended. Blokuje to dostęp dla modeli Bard (Gemini) oraz Vertex AI, nie wpływając na SEO. Warto dodać, że wprowadzono to we wrześniu 2023 roku.
Źródło: Blog Google (The Keyword) – An update on web publisher controls
Konfiguracja specjalistycznych robotów dla Zakupów Google oraz usługi Google News
Na koniec warto wspomnieć, że Google to nie jest jeden wielki robot, ale cała armia wyspecjalizowanych agentów, z których każdy ma swoje konkretne zadanie i wymaga od ciebie nieco innego podejścia. Jeśli prowadzisz sklep internetowy, twoim najlepszym przyjacielem powinien zostać Storebot-Google, bo to on odpowiada za sprawdzanie cen i dostępności twoich towarów. Jeśli zablokujesz go przez pomyłkę lub zaniedbanie, twoje produkty mogą przestać się wyświetlać w Zakupach Google, a to prosta droga do spadku sprzedaży. Ten robot musi mieć swobodny dostęp do kart produktów, aby klienci nie widzieli nieaktualnych cen, co buduje zaufanie i zapobiega frustracji. Z kolei dla wydawców portali informacyjnych kluczowy jest Googlebot-News, który rządzi się swoimi prawami i decyduje o tym, co trafi do sekcji z wiadomościami. Tutaj liczy się czas i struktura – możesz skonfigurować swoją stronę tak, by robot wiedział dokładnie, gdzie szukać najnowszych newsów, a które sekcje, jak na przykład regulamin czy archiwum, omijać szerokim łukiem. Jeszcze innym przypadkiem jest robot AdSense, który skanuje twoją treść nie po to, by ją indeksować w wyszukiwarce, ale po to, by dopasować do niej reklamy, które dadzą ci zarobek. Zablokowanie go to strzał w stopę, bo reklamy staną się mniej trafne, a twoje przychody spadną. Każdy z tych robotów szanuje ogólne zasady z pliku robots.txt, ale daje ci też możliwość tworzenia dedykowanych reguł tylko dla niego. To potężne narzędzie w rękach świadomego webmastera, pozwalające na chirurgiczną precyzję w zarządzaniu tym, jak różne części ekosystemu Google widzą twoją witrynę. Zrozumienie roli każdego z tych botów pozwala ci optymalizować stronę pod kątem konkretnych celów biznesowych, czy to będzie sprzedaż butów, dostarczanie newsów, czy zarabianie na reklamach. Nie traktuj ich wszystkich jedną miarą, bo to, co dobre dla ogólnego SEO, niekoniecznie musi być optymalne dla kampanii produktowej czy newsowej. Kluczem do sukcesu jest tutaj elastyczność i ciągłe monitorowanie, jak poszczególne roboty radzą sobie z twoją witryną.
Żródło : https://developers.google.com/crawling






